FAKER.GPT: Generate JSON of Fake (but realistic) Data

The process of creating realistic data isn't always easy, particularly when you are trying to scale the process. However, with innovative tools like GPT, the challenge can be significantly reduced. In this blog, we will explore a practical application of GPT in generating a structured JSON of realistic data — specifically, we will generate fake resume data of a hypothetical person.
This three-step method involves...
Creating a person's summary for random 'seed'
Generating a JSON-structured resume using the summary
Parsing the output for correctness.
Step 1: Creating a person's summary for a random 'seed'
Directly prompting GPT to 'generate a resume randomly' would not reach the desired level of randomness in the content. The generated resume will most of the times be biased towards Software developer or Business Management roles. To overcome the challenge, we will provide a seed for GPT to expand on. By specifying the exact fields to generate random content, we can expect more randomness in the content.
We ask GPT to create a summary of a person with the following prompt.
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
HumanMessage,
)
chat = ChatOpenAI(temperature=0.9)
question = """
Come up with a unique summary of a person using the following information.
Make sure that name is included in the summary. Expand on the occupation and education.\n
"""
question += f" - Name: {name}\n" if name else "- Name\n"
question += f" - Age: {age}\n" if age else "- Age\n"
question += f" - Occupation: {occupation}\n" if occupation else "- Occupation\n"
question += f" - Education: {education}\n" if education else "- Education\n"
question += f" - Work experience: {work_experience}\n" if work_experience else "- Work experience\n"
print("Generating a synthetic summary...\n")
resp = chat(([HumanMessage(content=message)]))
return {
"text": resp.content
}
Name, Age, Work experience, and Education are all a variable which you can pass a value into the prompt. Instead of fully relying on GPT, we can randomly select age or work experience so that the generated summary can be more diverse. I've also set the temperature to a higher value, to can expect more creativity in the output.
Below is an example of a generated summary.

Step 2: Generating a JSON-structured resume using the summary
With the individual's summary in hand, the next step is to pass the structure of the resume's JSON format and the summary to GPT. This involves defining a specific JSON structure that matches the typical sections of a resume, such as 'name, 'skills', 'work experience', 'educations', etc.
template = """
Generate a unique and realistic resume in the following JSON format:
---
{
"name": {
"raw": "",
"first": ""
"last": "",
"middle": "",
"title": ""
},
"phoneNumbers": ["", ""],
"websites": ["", ""],
"emails": ["", ""],
"dateOfBirth": "",
"location": {
"rawInput": ""
},
"objective": "",
"summary": "",
"totalYearsExperience": 0,
"educations": [
{
"organization": "",
"accreditation": "",
"grade": {
"raw": "",
"metric": "",
"value": ""
},
"location": {
"rawInput": ""
},
"dates": {
"completionDate": "",
"isCurrent": false,
"startDate": "",
"rawText": ""
}
}
],
"workExperience": [
{
"jobTitle": "",
"organization": "",
"location": {
"rawInput": ""
},
"jobDescription": "",
"dates": {
"completionDate": "",
"isCurrent": false,
"startDate": "",
"rawText": ""
}
}
]
}
"""
summary = summary.replace("\n", " ")
template = template + "\n The resume should be for " + summary
resp: AIMessage = chat(([HumanMessage(content=template)]))
With this structure and the summary from Step 1, we can prompt GPT to expand and generate content that conforms to the JSON structure.
Step 3: Use an Output Parser to Ensure Correct JSON Format
The final step in this process is to verify the output from GPT to ensure it adheres to the correct JSON format. It's important to note that while GPT is impressive in its ability to generate coherent and contextually relevant text, it's not flawless. There can be instances where the generated output may not perfectly fit the JSON format. It can hallucinate some fields too. For this reason, we need to implement an output parser to check and rectify any potential formatting issues. We can use LangChain's OutputFixingParser for this task.
OutputFixingParser relies on Pydantic for data validation and parsing. Pydantic allows us to define data schemes with Python classes and it automatically generates code to enforce the schemas.
The resume schema looks like this.
class Resume(BaseModel):
name: Name = Field(description="name of person")
phoneNumbers: List[str] = Field(description="list of phone numbers")
websites: List[str] = Field(description="list of websites")
emails: List[str] = Field(description="list of emails")
dateOfBirth: str = Field(description="date of birth")
location: Location = Field(description="location of person")
objective: str = Field(description="objective of person")
summary: str = Field(description="summary of person")
totalYearsExperience: int = Field(description="total years of experience")
educations: List[Education] = Field(description="list of educations")
workExperience: List[WorkExperienceDate] = Field(description="list of work experiences")
And then define the OutputFixingParser as follows.
from langchain.output_parsers import OutputFixingParser
generated_json = ai_resp.content
parser = PydanticOutputParser(pydantic_object=Resume)
try:
print("Trying to parse...")
res: Resume = parser.parse(generated_json)
except Exception as e:
print("Error in JSON... Fixing...")
# Takes in the error message from the parser and send it to GPT to fix the misformatted json
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
res = new_parser.parse(generated_json)
print(res.json())
When there is a parsing issue, the error message is passed to the OutputFixingParser, which is another GPT another the hood. OutputFixingParser will look at the error message and the malformed JSON to correctly format it. This parser can address issues such as missing braces or quotation marks, incorrect comma placements, and more.
Step 4: Putting it all together; DEMO
The final output JSON looks like this. You can see that each field is populated with realistic data. This is expensive to do it manually but with GPT we can scale it up easily.
{
"name":{
"raw":"Jane Smith",
"first":"Jane",
"last":"Smith",
"middle":"",
"title":""
},
"phoneNumbers":[
"(123) 456-7890",
"(987) 654-3210"
],
"websites":[
"janesmith.com",
""
],
"emails":[
"jane.smith@email.com",
""
],
"dateOfBirth":"01/01/1980",
"location":{
"rawInput":"New York, NY"
},
"objective":"",
"summary":"Talented and accomplished professional with a passion for education. Over a decade of experience as a teacher and mentor and a proven track record of success in leadership roles in various academic institutions.",
"totalYearsExperience":10,
"educations":[
{
"organization":"Prestigious University",
"accreditation":"Bachelor of Education",
"grade":{
"raw":"4.0",
"metric":"GPA",
"value":"4"
},
"location":{
"rawInput":"New York, NY"
},
"dates":{
"completionDate":"05/01/2005",
"isCurrent":false,
"startDate":"08/01/2001",
"rawText":"08/01/2001 - 05/01/2005"
}
}
],
"workExperience":[
{
"jobTitle":"Lead Teacher",
"organization":"ABC School",
"location":{
"rawInput":"New York, NY"
},
"jobDescription":"Developed and implemented curriculum for students in grade 5. Mentored new teachers and contributed to the development of school-wide policies.",
"dates":{
"completionDate":"05/01/2010",
"isCurrent":false,
"startDate":"08/01/2005",
"rawText":"08/01/2005 - 05/01/2010"
}
},
{
"jobTitle":"Assistant Principal",
"organization":"XYZ School",
"location":{
"rawInput":"Brooklyn, NY"
},
"jobDescription":"Managed day-to-day operations of school. Worked with teachers to improve student outcomes and oversaw the implementation of new programs.",
"dates":{
"completionDate":"",
"isCurrent":true,
"startDate":"08/01/2010",
"rawText":"08/01/2010 - Present"
}
}
]
}
Since we know exactly how the JSON is structured we can also create a template for a resume and automatically populate it for better human-readability. I've provided the JSON schema and asked ChatGPT to create an HTML template of a resume.

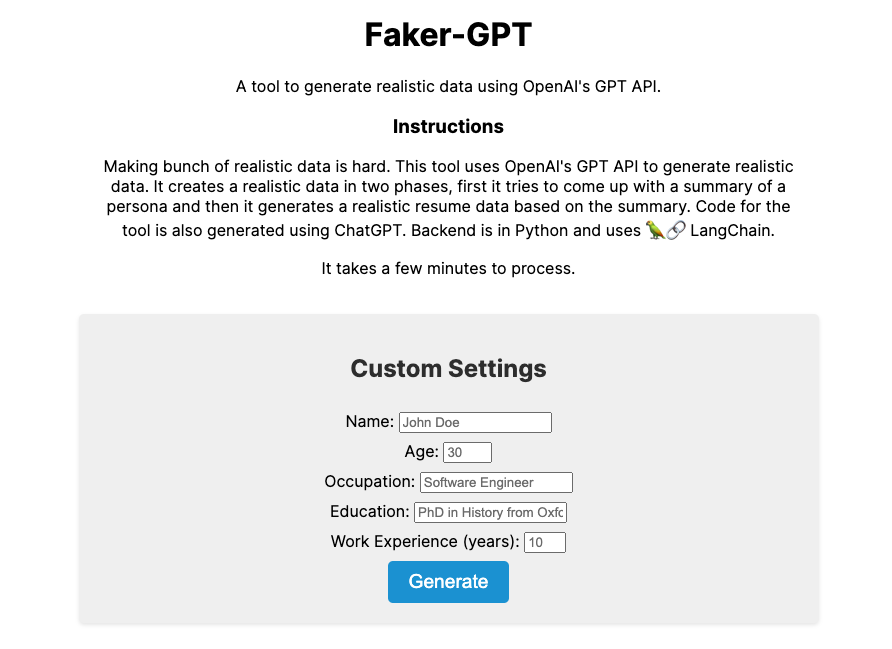
I've put together a simple DEMO here for you to try out!
To sum it up, with GPT's prowess in generating realistic and coherent text and a systematic approach to define the data structure and validate the output, we can automate the creation of structured and realistic data.
This approach is not limited to resumes, of course. Any structured data that can be represented in JSON format, such as user profiles, business records, or product catalogues, can be generated using this method.
However, it's crucial to remember that the quality and the randomness of the generated data heavily depend on the prompts used to generate the initial summary and the subsequent JSON filling prompts.
GPT presents a scalable solution for the automation of realistic data generation. As we continue to advance in the field of AI and machine learning, methods like these will only become more refined, opening up a world of possibilities for data generation and beyond.
The use of GPT for synthetic data generation poses fascinating opportunities for various fields, including but not limited to software testing, machine learning model training, and UI/UX design prototyping. By using the techniques outlined in this blog post, you can start exploring these possibilities and harness the power of AI to streamline your data generation tasks.
PS
At Seeai, we help LLM-powered software development. For any question contact us here!





