How to Create an App that Answers Questions About Your Contract Using Embeddings and GPT

Contracts tend to be long and boring. Especially when you have to read the whole thing just to answer a single question. Creating an app that can answer questions about specific contracts can be a massive time-saver for businesses and individuals alike.
This guide will show you how to create an app that combines OpenAI embeddings, which are cost-effective, with the powerful processing capabilities of GPT. This method will allow your app to have context from all relevant documents while still remaining affordable.
Method
1. Compute embedding of your contract and store results in a vector database
2. Convert User Questions to Embeddings and Search for Related Embeddings
3. Use GPT to Answer the User's Question with the Relevant Sections as Context
Compute Embedding of Your Contract and Store Results in a Vector Database
The first step in creating your app is to run your contract through the OpenAI embeddings API. This API generates a dense vector representation of your contract's text, capturing the semantic relationships between words and phrases.
First, we need to extract the text from the contract. We do this by using PyPDF2 library.
def extract_text_from_binary(file):
pdf_data = io.BytesIO(file)
reader = PyPDF2.PdfReader(pdf_data)
num_pages = len(reader.pages)
text = ""
for page in range(num_pages):
current_page = reader.pages[page]
text += current_page.extract_text()
return text
Usually, the text will lose its structure and formatting after going through PDF extraction. We want to split the extracted text into smaller chunks. This is to reduce the computational and financial costs. Here I wrote a simple function which splits the given text into smaller chunks of words and also ensure that the chunk ends in a sentence.
def split_text(text, word_limit):
words = text.split()
sections = []
current_section = []
word_count = 0
for word in words:
word_count += 1
current_section.append(word)
if word_count >= word_limit:
# Check if the word ends with a sentence-ending punctuation
if re.search(r'[.!?]', word):
sections.append(' '.join(current_section))
current_section = []
word_count = 0
# Add the remaining words to the last section
if current_section:
sections.append(' '.join(current_section))
return sections
You can obtain these embeddings by sending a request to the OpenAI API with extracted text as input. LangChain library makes our life easier with just two lines of code.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(sections, embeddings, persist_directory=str(database_path))
docsearch.persist()
Chroma is an Open Source Vector Database. It has built-in integration with LangChain. Unlike PineCone which is popular but expensive, Chroma is free to use. ChromaDB allows you to perform fast and efficient similarity searches, which will be essential in finding the most relevant sections of your contract when answering user questions.
With just these two lines, we have created an embedding from the text and the result is stored in Chroma database.
Convert User Questions to Embeddings and Search for Related Embeddings
# user_question
docs = docsearch.similarity_search(user_question)
When you have a question about your contract, you first need to convert the question into an embedding. You can do this by running similarity_search method on docsearch. This will internally convert the user_question into an embedding, just as you did with your contract text. Once it has the question's embedding, the vector database will search and return the related embeddings in your contract. These related embeddings will likely correspond to sections of your contract that are relevant to the question.
Use GPT to Answer the User's Question with the Relevant Sections as Context
Now that you have the embeddings from your contract, you can use GPT to answer the user's question. First, convert the embeddings back into their corresponding paragraphs or sections of the contract.
contract_text = ""
for doc in docs:
contract_text += doc.page_content
Then, send these paragraphs to the GPT API along with the user's original question. GPT will use the context provided by the paragraphs to generate a coherent and accurate answer to the user's question.
template = """
You are an expert legal advisor.
Read the following excerpt from a contract and answer the question that follows.
---
{contract_text}
---
{human_input}"""
prompt = PromptTemplate(
input_variables=["human_input", "contract_text"],
template=template
)
llm_chain = LLMChain(
llm=OpenAIChat(model="gpt-3.5-turbo"),
prompt=prompt,
verbose=False,
)
res = llm_chain.predict(human_input=user_input, contract_text=contract_text)
print(res)
I found gpt-3.5-turbo to perform very well and the best value for the cost.
And that is it for the core method. Very simple!
I also put together a simple HTML for a simple DEMO! I'm using FastAPI for the backend and deployed it on Render.
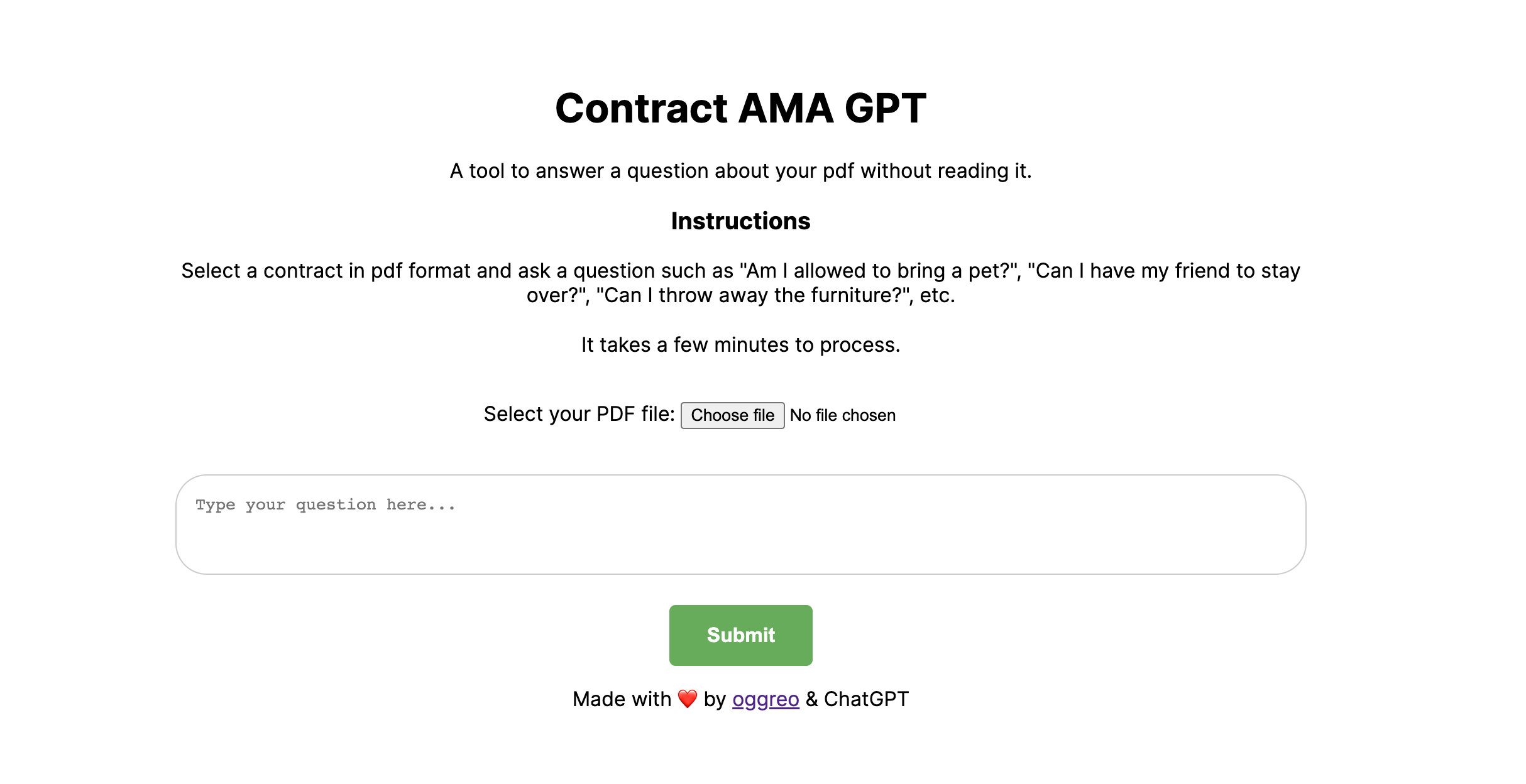
You can upload a contract in a pdf format along with a question to have GPT answer your query.
Result
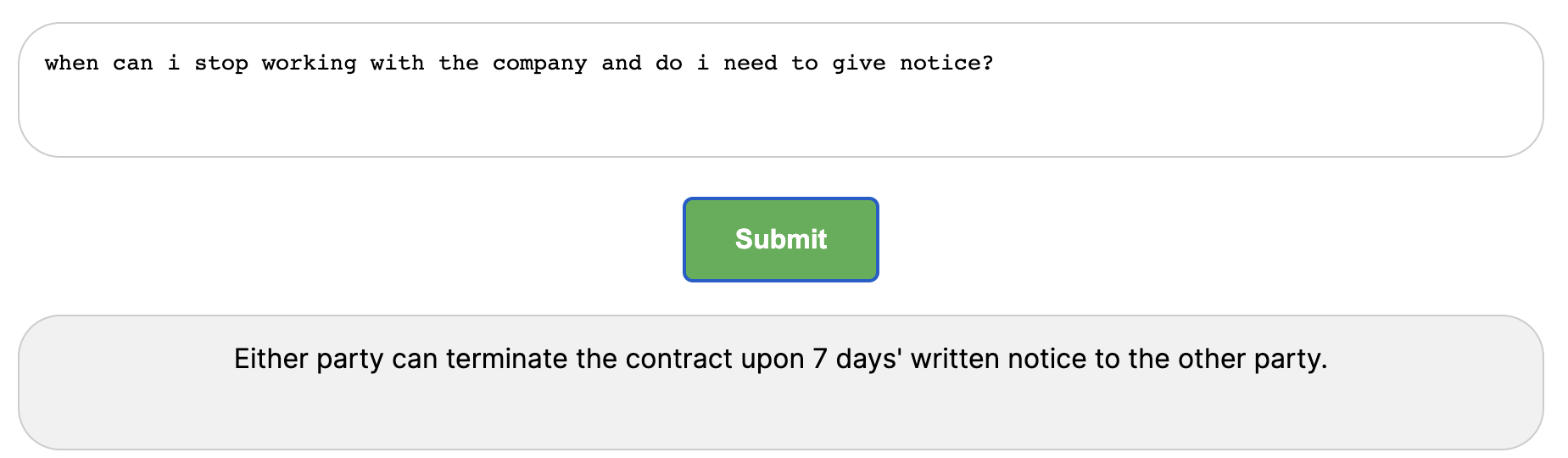
Asking a question about my work contract...
Asking a question about the tenancy contract...
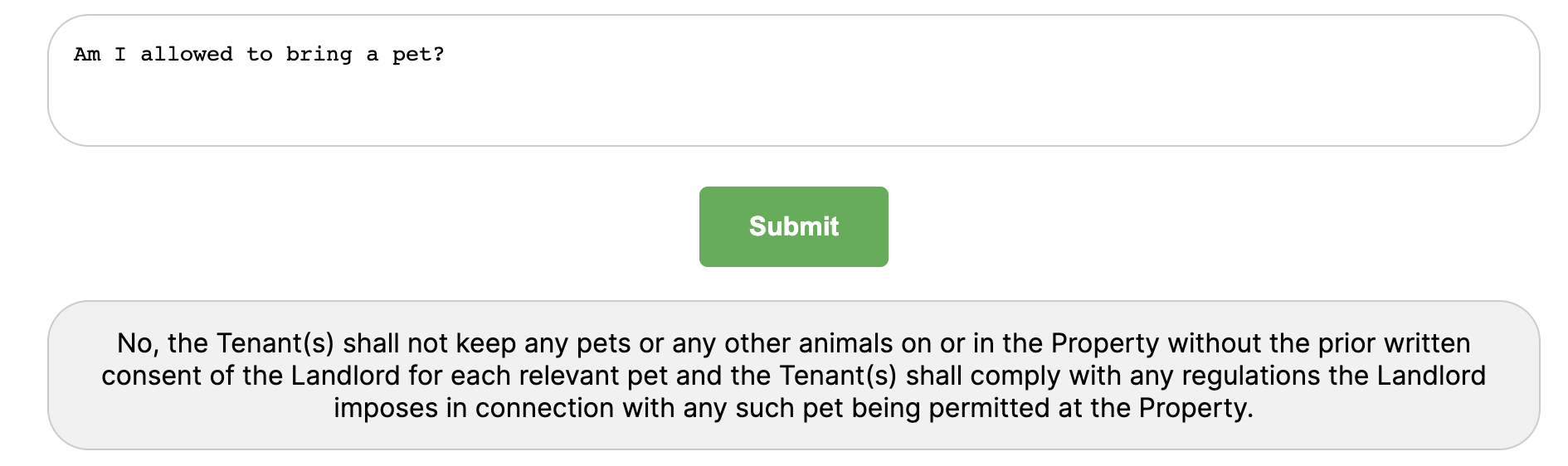
Works very well.
Again, if you want to give it a try, you can do it from here.
I said contract but the same method works for any document :)
Hope you enjoyed it! I am doing a weekly hacking session using GPT and I will be sharing what I built here so make sure to follow!




